physical memory managemen
物理内存管理
Linux的内存管理可分为物理内存管理和虚拟内存管理。所谓的虚拟内存就是指程序中使用的地址(32位系统可以使用4GB的虚拟内存地址),而物理地址是指计算机上真实安装的内存(例如我们安装了一条256MB的内存条,那么物理内存就只有256MB,但虚拟内存地址依然有4GB)。Linux内核需要通过一个映射关系才能把虚拟地址转换成物理地址,下面就来介绍Linux内存管理的细节。
内存管理区
Linux把物理内存划分为内存页进行管理, 一个内存页的大小为4KB, 所以在物理内存为1GB的电脑中可以分为 262144 (计算公式为: 1024*1024*1024/1024/4) 个内存页. Linux定义了一个名为page的结构体来描述物理内存页, 定义如下:
typedef struct page {
struct list_head list; // 这个页在不同的链表中的节点
struct address_space *mapping; // 这个页所属的地址空间
unsigned long index; // 这个页在地址空间中的位置索引
struct page *next_hash; // 哈希表指针, 指向哈希冲突链中的下一个页
atomic_t count; // 引用计数器, 表示这个页被多少个用户使用
unsigned long flags; // 页的标志位
struct list_head lru; // 页在LRU链表中的节点, 用于内存回收
unsigned long age; // 页的年龄, 用于内存回收算法
wait_queue_head_t wait; // 等待队列, 当页被锁定时, 其他进程可以在这个队列中等待
struct page **pprev_hash; // 哈希表指针, 指向前一个节点的next_hash指针, 用于O(1)时间复杂度的删除操作
struct buffer_head * buffers; // 页对应的缓冲区链表, 用于文件系统的页缓存
void *virtual; // 页的虚拟地址, 仅在内核空间使用
struct zone_struct *zone; // 页所属的内存区, 用于内存分配和回收
} mem_map_t;
void __init free_area_init_core(int nid, pg_data_t *pgdat, struct page **gmap,
unsigned long *zones_size, unsigned long zone_start_paddr,
unsigned long *zholes_size, struct page *lmem_map) // 初始化内存页结构数组
{
...
totalpages = 0;
for (i = 0; i < MAX_NR_ZONES; i++) {
unsigned long size = zones_size[i];
totalpages += size; // 计算系统中有多少个内存页
}
realtotalpages = totalpages;
if (zholes_size)
for (i = 0; i < MAX_NR_ZONES; i++)
realtotalpages -= zholes_size[i]; // 减去内存洞的页数
...
// 一些架构(如x86)需要在内核映射区之外的地方放置mem_map数组, 因此它们(和它们的
// 大小)被传递到这个函数中. 其他架构(如ppc)直接在内核映射区放置mem_map数组, 因此它们传递NULL和0.
// 对于不连续内存模型,概念上的内存映射数组从PAGE_OFFSET开始,
// 我们需要将实际数组对齐到内存映射边界,以便MAP_NR能够正常工作。
map_size = (totalpages + 1)*sizeof(struct page);
if (lmem_map == (struct page *)0) {
lmem_map = (struct page *) alloc_bootmem_node(pgdat, map_size); // 分配page结构数组
lmem_map = (struct page *)(PAGE_OFFSET +
MAP_ALIGN((unsigned long)lmem_map - PAGE_OFFSET)); // 对齐原理:确保mem_map数组的起始地址是页面大小的倍数
}
...
}
void __init free_area_init(unsigned long *zones_size)
{
free_area_init_core(0, &contig_page_data, &mem_map, zones_size, 0, 0, 0);
}
totalpages, 然后通过alloc_bootmem_node()分配page结构数组. 初始化后的内存结构如下图:
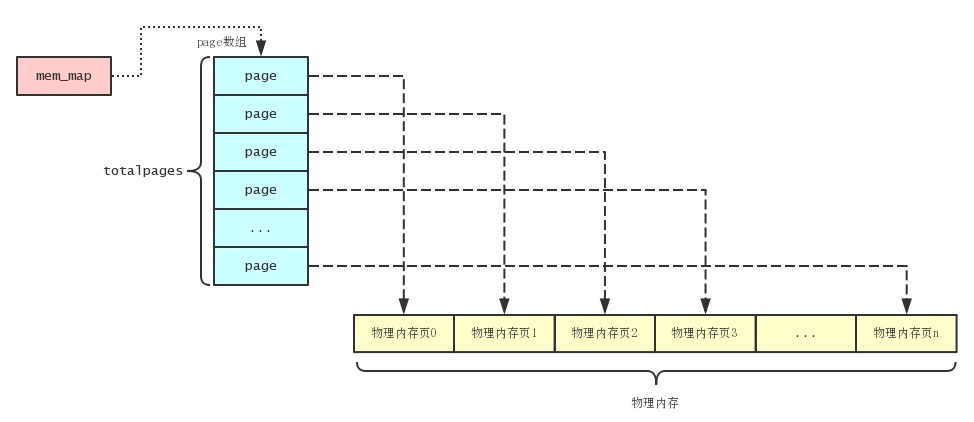
除了使用page结构管理内存外, Linux还根据不同的用途把内存划分为不同的区域, 主要分为3个内存区域: ZONE_DMA, ZONE_NORMAL 和 ZONE_HIGHMEM. ZONE_DMA是 小于等于16MB 的内存地址, 而ZONE_NORMAL是 大于ZONE_DMA小于等于896MB 的内存地址, ZONE_HIGHMEM则是 大于896MB 的内存地址.
Linux使用 zone_struct 结构体来管理不同的内存区域, 其定义如下:
#define MAX_ORDER 10 // 伙伴系统算法中最大的订单, 表示分配2^10=1024页的内存块
typedef struct free_area_struct {
struct list_head free_list; // 空闲内存块链表, 每个链表中的内存块大小为2^order页
unsigned int *map; // 用于标记内存块的使用情况,map[i]的值为0表示第i个内存块空闲, 为1表示第i个内存块已被分配
} free_area_t;
typedef struct zone_struct {
/*
* 普通字段:
*/
spinlock_t lock; // 保护zone_struct结构体的自旋锁, 在访问或修改zone_struct结构体的字段时需要先获取这个锁
unsigned long offset; // 表示当前区在mem_map中的起始页面号, 对于ZONE_NORMAL区来说, offset就是ZONE_DMA区的页面数
unsigned long free_pages; // 当前区的空闲页面数
unsigned long inactive_clean_pages; // 当前区的非活跃干净页面数, 这些页面可以直接回收
unsigned long inactive_dirty_pages; // 当前区的非活跃脏页面数, 这些页面需要先写回磁盘才能回收
unsigned long pages_min, pages_low, pages_high; // 水位线, 当free_pages小于pages_low时, 内核会尝试回收一些页面;
// 当free_pages小于pages_min时, 内核会强制回收一些页面;
// 当free_pages大于pages_high时, 内核认为内存充足
/*
* 伙伴系统算法字段:
*/
struct list_head inactive_clean_list; // 非活跃干净页面链表, 这些页面可以直接回收
free_area_t free_area[MAX_ORDER]; // 用于伙伴分配算法
/*
* 很少用的字段:
*/
char *name;
unsigned long size;
/*
* 不连续内存模型字段:
*/
struct pglist_data *zone_pgdat;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
struct page *zone_mem_map;
} zone_t;
内存节点(struct pglist_data), 现代计算机存储架构可分为: 非一致性内存架构(NUMA) 和 一致性内存架构(UMA). UMA是指介质均匀的(访问速度一致), 地址连续的存储架构. 对于这种内存架构, 系统访问任何内存地址的速度都是一样的. 但对于现代SMP(对称多处理器)架构的系统, UMA内存架构就不太适用, 因为对于多核CPU, 每个核心都有自己的本地内存, 而且访问本地内存的速度要比访问非本地内存的速度快很多, 像这种有多种不同介质和访问速度的内存架构叫NUMA.
在NUMA内存架构中, Linux定义了一个 pglist_data 的结构体来管理不同介质和访问速度的内存节点. 定义如下:
#define NR_GFPINDEX 0x100 // GFP分配标志的最大值, 也就是分配策略的数量, 256个分配策略
typedef struct pglist_data {
zone_t node_zones[MAX_NR_ZONES]; // 内存节点中的内存管理区数组, 每个内存节点可以有多个内存管理区
// 例如ZONE_DMA, ZONE_NORMAL和ZONE_HIGHMEM
zonelist_t node_zonelists[NR_GFPINDEX]; // 内存节点中的分配策略数组, 每个分配策略对应一个zonelist_t结构体,
// 用于指定分配内存时的优先级和限制条件
struct page *node_mem_map; // 内存节点中的page结构数组, 用于管理内存页的状态和属性
unsigned long *valid_addr_bitmap; // 内存节点中的有效地址位图, 用于标记哪些物理地址是有效的, 哪些是无效的
struct bootmem_data *bdata; // 内存节点中的引导内存数据结构, 用于在系统启动时管理内存的分配和释放
unsigned long node_start_paddr; // 内存节点的起始物理地址, 用于计算内存页的物理地址
unsigned long node_start_mapnr; // 内存节点的起始页面号, 用于计算内存页在mem_map数组中的索引
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
} pg_data_t;
内存节点(pglist_data), 接着是 内存管理区(zone_struct), 最后才到 内存页(page). 三者的关系如下图:
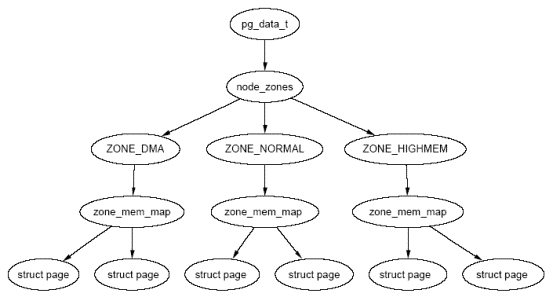
所以Linux分配内存时首先找到合适的内存节点, 然后再到指定的内存区(DMA, NORMAL或者HIGHMEM)中分配一定数量的内存页. 由于内存区分配内存时使用的是伙伴系统算法, 所以分配出来的内存页物理地址一定是连续的.
物理内存页分配
Linux内核使用 alloc_pages() 函数来进行分配物理内存页,alloc_pages()函数的原型如下:
struct page * alloc_pages(int gfp_mask, unsigned long order);
gfp_mask 是分配策略, 而 order 是分配 1<<order 个页面.
Linux内核有UMA和NUMA两个版本的alloc_pages(), 为了简单起见, 我们直接选用UMA版本的, 因为UMA只有一个内存节点. 我们先来看看UMA版本的alloc_pages()源码:
static bootmem_data_t contig_bootmem_data;
pg_data_t contig_page_data = { bdata: &contig_bootmem_data };
static inline struct page * alloc_pages(int gfp_mask, unsigned long order)
{
/*
* Gets optimized away by the compiler.
*/
if (order >= MAX_ORDER)
return NULL;
return __alloc_pages(contig_page_data.node_zonelists+(gfp_mask), order);
}
contig_page_data 来存储. 前面我们介绍过 struct pglist_data 结构, node_zonelists 字段是不同的分配策略的数组, 可以通过数组的下标来指定分配策略. Linux内核定义的分配策略下标有以下几种:
// 标志位
#define __GFP_WAIT 0x01
#define __GFP_HIGH 0x02
#define __GFP_IO 0x04
#define __GFP_DMA 0x08
#ifdef CONFIG_HIGHMEM
#define __GFP_HIGHMEM 0x10
#else
#define __GFP_HIGHMEM 0x0 /* noop */
#endif
// 分配策略
#define GFP_BUFFER (__GFP_HIGH | __GFP_WAIT)
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_USER (__GFP_WAIT | __GFP_IO)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_HIGHMEM)
#define GFP_KERNEL (__GFP_HIGH | __GFP_WAIT | __GFP_IO)
#define GFP_NFS (__GFP_HIGH | __GFP_WAIT | __GFP_IO)
#define GFP_KSWAPD (__GFP_IO)
#define GFP_DMA __GFP_DMA
#define GFP_HIGHMEM __GFP_HIGHMEM
node_zonelists 数组的大小是256, 所以下标15以后的分配策略是永远都不会访问到的. Linux为什么要定义这么大数组呢, 难道是为了以后扩展?
我们在来看看怎么初始化一个内存节点中的分配策略, 分配策略的初始化是在 build_zonelists() 函数中完成:
#define NR_GFPINDEX 0x100 // 10进制是256
static inline void build_zonelists(pg_data_t *pgdat)
{
int i, j, k;
for (i = 0; i < NR_GFPINDEX; i++) {
zonelist_t *zonelist;
zone_t *zone;
zonelist = pgdat->node_zonelists + i;
memset(zonelist, 0, sizeof(*zonelist));
zonelist->gfp_mask = i;
j = 0;
k = ZONE_NORMAL;
if (i & __GFP_HIGHMEM)
k = ZONE_HIGHMEM;
if (i & __GFP_DMA)
k = ZONE_DMA;
switch (k) {
default:
BUG();
/*
* fallthrough:
*/
case ZONE_HIGHMEM:
zone = pgdat->node_zones + ZONE_HIGHMEM;
if (zone->size) {
#ifndef CONFIG_HIGHMEM
BUG();
#endif
zonelist->zones[j++] = zone;
}
case ZONE_NORMAL:
zone = pgdat->node_zones + ZONE_NORMAL;
if (zone->size)
zonelist->zones[j++] = zone;
case ZONE_DMA:
zone = pgdat->node_zones + ZONE_DMA;
if (zone->size)
zonelist->zones[j++] = zone;
}
zonelist->zones[j++] = NULL;
}
}
zonelist 添加不同的内存管理区.分配策略大概的规则如下:
- 如果设置了
__GFP_HIGHMEM标志, 那么就把ZONE_HIGHMEM内存管理区添加到zonelist中. - 如果设置了
__GFP_DMA标志, 那么就把ZONE_DMA内存管理区添加到zonelist中. - 如果既没有设置
__GFP_HIGHMEM标志也没有设置__GFP_DMA标志, 那么就把ZONE_NORMAL内存管理区添加到zonelist中.
现在回头来看看 __alloc_pages() 函数的实现, 由于这个函数比较长, 所以我们分段开看:
struct page * __alloc_pages(zonelist_t *zonelist, unsigned long order)
{
zone_t **zone;
int direct_reclaim = 0;
unsigned int gfp_mask = zonelist->gfp_mask;
struct page * page;
memory_pressure++;
if (order == 0 && (gfp_mask & __GFP_WAIT) &&
!(current->flags & PF_MEMALLOC))
direct_reclaim = 1; // 是否申请单个内存页并且可以阻塞的
// 可用物理内存页是否足够
if (inactive_shortage() > inactive_target / 2 && free_shortage())
wakeup_kswapd(0);
// 脏页面是否过多
else if (free_shortage() && nr_inactive_dirty_pages > free_shortage()
&& nr_inactive_dirty_pages >= freepages.high)
wakeup_bdflush(0);
direct_reclaim 变量设置为1. 然后判断可用物理内存页是否足够, 如果不足就调用 wakeup_kswapd() 唤起kswapd内核线程进行回收一些物理内存页. 另外, 如果可用物理内存页不足时还需要判断非活跃脏页面是否超过一定的数量, 如果超过了就调用 wakeup_bdflush() 唤醒 bdflush 内核线程, 把脏页面写到磁盘中.
try_again:
/*
* First, see if we have any zones with lots of free memory.
*
* We allocate free memory first because it doesn't contain
* any data ... DUH!
*/
zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
if (!z->size)
BUG();
if (z->free_pages >= z->pages_low) {
page = rmqueue(z, order);
if (page)
return page;
} else if (z->free_pages < z->pages_min &&
waitqueue_active(&kreclaimd_wait)) {
wake_up_interruptible(&kreclaimd_wait);
}
}
rmqueue() (使用伙伴系统算法分配, 下面会介绍)从内存管理区的空闲页面队列中分配内存页, 如果成功了就直接返回申请到的内存页. 如果内存管理区的空闲内存页小于最低水位时, 那么就唤醒 kreclaimd 内核线程释放内存管理区一些非活跃的并且干净的内存页给系统.
page = __alloc_pages_limit(zonelist, order, PAGES_HIGH, direct_reclaim);
if (page)
return page;
page = __alloc_pages_limit(zonelist, order, PAGES_LOW, direct_reclaim);
if (page)
return page;
__alloc_pages_limit() 函数来分配, 这个函数主要是把分配内存时的条件放宽一些, 这样就更容易分配到内存页.
wakeup_kswapd(0);
if (gfp_mask & __GFP_WAIT) {
__set_current_state(TASK_RUNNING);
current->policy |= SCHED_YIELD;
schedule();
}
page = __alloc_pages_limit(zonelist, order, PAGES_MIN, direct_reclaim);
if (page)
return page;
kswapd 内核线程. 如果申请内存的进程设置了可以阻塞的标志, 那么就先让出CPU, 让 kswapd 内核线程先回收一些内存页. 接着接续调用 __alloc_pages_limit() 尝试申请内存页, 如果成功直接返回.
if (!(current->flags & PF_MEMALLOC)) {
if (order > 0 && (gfp_mask & __GFP_WAIT)) {
zone = zonelist->zones;
/* First, clean some dirty pages. */
current->flags |= PF_MEMALLOC;
page_launder(gfp_mask, 1);
current->flags &= ~PF_MEMALLOC;
for (;;) {
zone_t *z = *(zone++);
if (!z)
break;
if (!z->size)
continue;
while (z->inactive_clean_pages) {
struct page * page;
/* Move one page to the free list. */
page = reclaim_page(z);
if (!page)
break;
__free_page(page);
/* Try if the allocation succeeds. */
page = rmqueue(z, order);
if (page)
return page;
}
}
}
page_launder() 函数来把一些脏页面写到磁盘, 再尝试申请内存页.
if ((gfp_mask & (__GFP_WAIT|__GFP_IO)) == (__GFP_WAIT|__GFP_IO)) {
wakeup_kswapd(1);
memory_pressure++;
if (!order)
goto try_again;
} else if (gfp_mask & __GFP_WAIT) {
try_to_free_pages(gfp_mask);
memory_pressure++;
if (!order)
goto try_again;
}
}
(__GFP_WAIT|__GFP_IO) 标志, 那么就唤醒 kswapd 内核线程, 并等待其执行完毕. 如果只设置了 __GFP_WAIT 标志, 那么就调用 try_to_free_pages() 尝试释放一些内存页.
zone = zonelist->zones;
for (;;) {
zone_t *z = *(zone++);
struct page * page = NULL;
if (!z)
break;
if (!z->size)
BUG();
if (direct_reclaim) {
page = reclaim_page(z);
if (page)
return page;
}
/* XXX: is pages_min/4 a good amount to reserve for this? */
if (z->free_pages < z->pages_min / 4 &&
!(current->flags & PF_MEMALLOC))
continue;
page = rmqueue(z, order);
if (page)
return page;
}
return NULL;
PF_MEMALLOC 标志 (一般都是回收内存页的进程, 所以这些进程需要内存时必须满足他们, 因为满足他们能够获得更多的空闲内存页), 并且内存管理区空闲内存页大于最低水位的四分之一, 那么还是尝试调用 rmqueue() 来说申请内存页. 如果都失败的话, 那么只能返回NULL了.